Release notes¶
Disco 0.5.4 (October 27, 2014)¶
New features¶
- A lot of new examples including ipython, page rank, and travelling salesman problem.
- Add a deployment script to get a cluster ready in Google Cloud in a couple of minutes.
- Fixes to let Disco run on OSX Yosemite.
- And a lot of bug fixes and performance improvements
Disco 0.5.3 (August 5, 2014)¶
New features¶
- There is now one event handler process for the events of each job. This resolves one of the bottlenecks in the disco master.
- plists is added as a new disco dependency for simple parallel list operations. The only use of this dependency at the moment is traversing the ddfs volumes in parallel in the build_map phase of GC.
- Job coordinator minimizes the amount of per-task work to avoid becoming a bottleneck for jobs with large number of tasks.
Disco 0.5.2 (June 24, 2014)¶
New features¶
- Ddfs can now distribute the blobs according to the amount of space available on the nodes.
- Disco now supports concurrent stages. That means, a stage can start before all of the tasks of the previous stages have finished. This option can be enabled for pipeline jobs.
- A Disco worker is available in golang <http://github.com/discoproject/goworker>. This worker only supports map-reduce jobs at the moment.
- The scheduler dictionary can now be sent as part of the job_dict in both the classic and the pipeline workers. The max_core option in this dictionary will limit the number of tasks from a job that can run.
- By default, Disco is now installed in /usr instead of /usr/local.
Deprecated¶
- The deprecated merge_partitions option has been removed.
Disco 0.5.1 (April 16, 2014)¶
New features¶
- Disco now uses folsom for monitoring purposes. Folsom extracts some information from Disco and sends it to a graphite server. The folsom (and related) applications will start only if DISCO_PROFILE is set. This is not set by default. By default, folsom assumes that the localhost is the graphite server. This can be overriden by using the GRAPHITE_HOST option.
- A docker file has been added that lets you install Disco in a Docker container.
- A spec file has been added to make it easy to create an rpm from the a Disco tarball.
- Disco now works with Erlang 17.
Experimental¶
- Disco now supports reading the job inputs from and writing the job outputs to HDFS.
- Disco now supports reading the job inputs from and writing the job outputs to Redis.
Changes¶
- The changes in the mochiweb fork of the Disco project has been merged into upstream and Disco is now using the upstream.
- New options are now passed to the erlang process on the master node that will disable scheduler compaction and spreads the schedulers as much as possible.
- Two options have been added to the ddfs chunk command to override the chunk size and the maximum record size.
- The save_info field has been added to the jobpack. For now, this field only contains the information needed for saving the outputs of the job into HDFS.
- A couple of examples have been added. Namely, the naive-bayes and an example for reading huge xml files. Moreover, the kclustering example has been re-implemented using the Disco pipelines.
Disco 0.5 (February 14, 2014)¶
This release is dedicated to the memory of Priya Hattiangdi, Prashanth Mundkur’s wife, who has passed away a few days ago. May she rest in peace.
New features¶
A new pipeline model for Disco job computation. This model is a conservative extension of the previous pure map-reduce model, and provides better support for certain kinds of processing that were previously implemented using chains of map-reduce jobs. This model also allows us to address various implementation issues and bugs in the previous map-reduce model.
However, there is almost complete backward-compatible support for the previous map-reduce model, with little or no change required to existing Disco jobs; but see below for restrictions.
Changes¶
The new pipeline model comes with several changes.
The current jobpack format has changed slightly, reflected by an incremented version in the version field. The main changes are in the fields of the jobdict. Jobpacks in the previous format are still supported; however, this support may be eventually removed in a future release.
The Disco worker protocol has also changed to support the pipeline model, which is again reflected by an incremented version field in the WORKER message. In particular, there are changes to the TASK, INPUT and OUTPUT protocol messages. There is no support for the previous version of the protocol, hence implementations of the Disco worker protocol will need to be updated to the current protocol version to work with this release. The standard Python and OCaml implementations support the new protocol.
The shuffle stage of the default map-reduce pipeline is now done as an explicit pipeline stage. When done after map, this results in a map_shuffle stage, whereas after reduce this becomes a reduce_shuffle stage.
In previous versions of Disco, these shuffles were performed in implicit stages within the Disco master itself, and actually implemented in Erlang. The shuffles now need to be performed in the Disco worker library code, and are implemented in both the Python and OCaml worker libraries.
A save_results field in the jobdict of the jobpack is now interpreted by the Disco master. Setting this to true tells the Disco master to save the job results into a DDFS tag.
Previously, this functionality was implemented in the Disco worker library, and required the library to implement DDFS client interface. Moving this to the master makes it easier to have this functionality in new language implementations of the Disco worker protocol and library. For example, this is used in the OCaml Disco library.
The web UI for jobs has changed slightly in order to show the stages of a job pipeline.
Disco now uses lager 2.0 which can be integrated with syslog.
Disco now works on FreeBSD 10.0.
A continuous integration has been set up to compile the Erlang code, and make sure it passes the dialyzer and all of the unittests.
Backwards incompatible changes¶
See above discussion of the Disco worker protocol.
Support for scheduler parameters in jobs (e.g. max_cores, force_local, and force_remote) has been removed. If present in a jobpack, they will be ignored.
Support for the use of partitions in a Disco job is now limited. Previously, this was typically used to set the number of reduce tasks: when set to a number N, it was guaranteed that the job would have N reduce tasks.
In this release, the number of reduce tasks is determined dynamically, using the user-generated labels attached to task outputs. Hence, it is possible for a job with partitions set to N to have less than N reduce tasks (if, for e.g. there were fewer than N task output labels generated by the maps). Since output labels in the default map-reduce pipeline are generated by the partition function, whether this discrepancy occurs depends on the partition function and the distribution of the inputs to it.
Chaining the non-DDFS results of a job executed in a previous version (pre-0.5) of Disco into a job executed with this version (0.5) of Disco is not supported.
Bugfixes¶
Please see the version control for the list of bug fixes.
Disco 0.4.5 (Mar 28, 2013)¶
Changes¶
- Disco documentation is now also at ReadTheDocs, along with documentation for DiscoDB.
- Mochiweb has been updated to fix compilation issues with Erlang 16B, which removed support for parameterized modules.
- Disco debian packages are no longer hosted on discoproject.org. Instead, Debian/Ubuntu users are encouraged to build their own packages for their particular Erlang/Python environment using the make-discoproject-debian script in the source tree. Please read the comments in the script.
Bugfixes¶
- Fix ddfs xcat display output, thanks to John Emhoff.
- Fix disco jobdict command (#341).
- Clarify the documentation in several places, thanks to feedback from Pavel Hančar, and fixes from John Emhoff.
- Fix a formatting bug in disco.util:urljoin.
- Fixed job deletion from UI when job has quotes in name, thanks to @nvdev on Github.
- Ensure that known garbage in DDFS is deleted immediately, without waiting for the safety timeout required for blobs and tags of indeterminate status.
Disco 0.4.4 (Dec 5, 2012)¶
New features¶
- The Python client library should now be Python3 compatible (version 3.2 or higher). As usual, the Python versions on the client and in the Disco cluster should match; mixed configurations are not supported. Since Python3 differentiates between string and unicode objects, Disco jobs will need to do the same. In particular, the default map_reader will provide bytes objects to the map function.
- Client and master version commands have been added to the disco command-line interface (issue #283). Currently, the client version command only works for Disco installed as a python egg.
- Installation support for NetBSD, thanks to Yamamoto Takashi.
- There is now a script to ease the creation of Disco debian packages, used to create the Debian packages provided from discoproject.org. Note that this script does not follow Debian packaging guidelines; use at your own risk!
- Small efficiency and logging improvements to DDFS.
Changes¶
- The disco and ddfs command-line scripts are now packaged as part of python-disco Debian package, so that they can be used on clients. Thanks to Daniel Graña.
Bugfixes¶
- disco.ddfs.DDFS.pull() should now obey DISCO_PROXY settings. Thanks to Daniel Graña.
- Intercept Python warning messages to sys.stderr, which break the Disco worker protocol. They are now logged as messages. Thanks to Daniel Graña.
- The HTTP header handling in the Disco client library is more case-resilient.
Disco 0.4.3 (Aug 22, 2012)¶
New features¶
- An extended Disco tutorial, thanks to Davin Potts.
- More documentation on using the proxy mode, and recovering from a master failure.
- More efficient (faster and using less memory) event_server, which should speed up UI responses for large jobs.
- Better fault-tolerance in re-replication, which should speed up node-removal. Node-removal of more than one node is now better tested and supported.
- Less unnecessary creation of garbage tags in DDFS, by avoiding creating new tag incarnations when their content has not changed. Since less garbage is created, GC will now complete more quickly.
- A “local-cluster” mode for DDFS, that simulates a multi-node DDFS cluster on a single machine. This is purely a developer feature for the purpose of improving DDFS testing, and cannot be used for running Disco jobs using DDFS. Thanks to Harry Nakos.
Changes¶
- Change the default partition function to use the key hash directly, instead of the string version of the key; this should address some unicode failures (#265). Thanks to quasiben and tmielika.
- Improved logging, especially to track re-replication progress.
- Major cleanup of Erlang codebase.
Bugfixes¶
- More fixes to DISCO_PROXY mode (#269). This mode is required for using DDFS in the “local cluster” mode.
- Fix a race when the UI tried to access information for a job that had been submitted but not yet unpacked (#304).
Disco 0.4.2 (Apr 26, 2012)¶
New features¶
- New fault-tolerant garbage collector and re-replicator (GC/RR).
- Allow scheduling of nodes for safe removal from DDFS (#201).
- Some useful GC statistics are now shown in the UI.
Changes¶
- Discodb and Discodex separated out into submodule repositories.
- Master/Erlang build switched to rebar, with source tree re-organized appropriately.
- Master logging switched to lager. Note that the format of the logs has changed as a result.
- Many dialyzer-related cleanups. Thanks to Kostis Sagonas.
- Cleanup of debian package build.
Bugfixes¶
- The new GC/RR closes #254, where a concurrent update to a tag was not handled at some points during GC.
- The new GC/RR also closes #256, where lost tag updates for re-replicated blobs caused later re-replication failures.
- Fix a case when the master node could run out of file descriptors when servicing an unexpectedly large number of jobpack requests from worker nodes (20d8fbe, 10a33b9, 0f7eaeb).
- Fixes to make DISCO_PROXY usable again (#269). Thanks to Dmitrijs Milajevs.
- Fix a crash due to an already started lock server (64096a3).
- Handle an existing disco user on package install (4f04e14). Thanks to Pedro Larroy.
- Fix a crash of ddfs_master due to timeouts in linked processes (#312).
Disco 0.4.1 (Sep 23rd 2011)¶
The official Disco repository is now at http://github.com/discoproject/disco
New features¶
- DiscoDB: ddb_cursor_count() added. iterator.count() is now faster.
- DiscoDB: Value lists are now stored in deltalists instead of lists during discodb construction, resulting to 50-75% smaller memory footprint in the many-values-per-key case.
Bugfixes¶
- Fix GC timeout issue (#268).
- Fix regression in Temp GC (09a1debb). Thanks to Jamie Brandon.
- Improved and fixed documentation. Thanks to Jens Rantil, stillinbeta and Luke Hoersten.
- Fix chunking. Thanks to Daniel Grana.
- Minor fixes in DiscoDB.
- Fix a bug in job pack extraction (e7b3b6).
Disco 0.4 (May 4th 2011)¶
New features¶
- The Disco Worker Protocol introduced to support custom workers, especially in languages besides Python (see ODisco for an OCaml worker now included in contrib).
- Complete overhaul of the Python disco.worker to support the new protocol. Most notably the worker is now completely self-contained - you do not have to install Python libraries on slave nodes anymore.
- Job History makes using the command-line less tedious. Several other enhancements to disco and ddfs command line tools.
- Setting up Disco is easier than ever. Updated Debian packaging and dependencies make Installing Disco System-Wide a breeze.
- More documentation, including a DiscoDB Tutorial using extended disco.job.Job classes.
- Throttling of messages coming from the worker, to prevent them from overwhelming the master without killing the process.
- Upgraded to mochiweb 2.0.
- Support for log rotation on the master via DISCO_ROTATE_LOG.
- prefix is now optional for jobs.
- Many Dialyzer-related improvements.
- Separate Debian branch containing rules to create Debian packages merged under pkg.
- Debian package for DiscoDB.
- disco.worker.classic.external - Classic Disco External Interface provides the task type on the command line, to allow a single binary to handle both map and reduce phases.
Bugfixes¶
- DDFS:
- important Recreating a previously deleted tag with a token did not work correctly. The call returned without an error but the tag was not created.
- Under some circumstances DDFS garbage collector deleted .partial files, causing PUT operations to fail (6deef33f).
Redundant inputs using the http:// scheme were not handled correctly (disco:// scheme worked ok) (9fcc740d).
Fix eaddrinuse errors caused by already running nodes (1eed58d08).
Fix newlines in error messages in the web UI.
The web UI no longer loses the filter when the events are refreshed.
Several fixes in node_mon. It should handle unavailable nodes now more robustly.
The OOB issue (#227) highlighted below became a non-issue as GC takes care of removing OOB results when the job is garbage collected.
Fix the issue with the job starting even when the client got an error when submitting a new job.
Deprecated¶
- disco.util.data_err(), disco.util.err(), and disco.util.msg(), have all been deprecated in favor of using raise and print statements.
- Jobs without inputs i.e. generator maps: See the raw:// protocol in disco.core.Disco.new_job().
- map_init and reduce_init deprecated. Use input_stream or reader instead.
- scheme_dfs removed.
- Deprecated DDFS_ROOT setting, use DDFS_DATA instead.
Disco 0.3.2 (Dec 6th 2010)¶
Note
In contrast to earlier releases, in 0.3.2 purging a job does not delete OOB results of the job automatically. This is listed as issue #227 and will be fixed in the next release together with other changes in OOB handling. Meanwhile, you can use disco.ddfs.DDFS.delete() to delete OOB results if needed.
New features¶
Built-in support for chunking large inputs (see Tutorial and disco.ddfs.DDFS.chunk()).
List of blacklisted nodes is persistent over restarts.
Disconnected nodes are now highlighted in the web UI.
Explicit hostname (tag://host/tag) is now allowed in tag urls.
- Some commonly used functions added to disco.func:
- disco.func.gzip_line_reader()
- disco.func.sum_combiner()
- disco.func.sum_reduce()
Job owner shown in the web UI (can be overridden with the DISCO_JOB_OWNER setting).
DISCO_WORKER_MAX_MEM setting can be used to limit the maximum amount of memory that can be used by a worker process.
- Disco Distributed Filesystem:
- Tags can now contain arbitrary user-defined attributes (see DDFS APIs and disco.ddfs.DDFS.setattr() and disco.ddfs.DDFS.getattr()).
- Basic token-based permission control for tags (see DDFS APIs).
- Improved REST API (see DDFS APIs).
- DDFS_PARANOID_DELETE setting allows an external program to be used to delete or verify obsolete files (see disco.settings).
Functions are now allowed in arguments of partial job functions.
Improved documentation, and a new document Administering Disco.
Bugfixes¶
- Several bugfixes in DDFS garbage collection.
- Tasks may be marked successful before results are persisted to disk (#208).
- Improved error handling for badly dying tasks (#162).
- Allow dots in DDFS paths (#196).
- Improved handling of out of memory conditions (#168, #200).
- Fix blocking net_adm:names in node_mon (#216).
- Fix a badmatch error on unknown jobname (#81).
- Fixed error handling if sort fails.
- Tutorial example fixed.
- HTTP error message made more informative.
Disco 0.3.1 (Sep 1st 2010)¶
Note
This release fixes a serious bug in how partition files are handled under certain error conditions. The bug has existed since Disco 0.1.
If a node becomes unavailable, for instance due to network congestion, master restarts the tasks that were running on the failed node on other nodes. However, it is possible that old tasks continue running on the failed node, producing results as usual. This can lead to duplicate entries being written to result files.
Note that not all task failures are suspectible to this bug. If the task itself fails, which is the most typical error scenario, Disco ensures that results are still valid. Only if your job events have contained messages like Node unavailable or Connection lost to the node, it is possible that results are invalid and you should re-run the suspected jobs with Disco 0.3.1 or newer.
This bug also revealed a similar issue with jobs that save their results to DDFS with save=True (available since Disco 0.3). It is possible that duplicate tasks create duplicate entries in the result tag. This is easy to detect and fix afterwards by listing urls in the tag and ensuring that there are no duplicates. A script is provided at util/fix-jobtag that can be used to check and fix suspected tags.
New features¶
- Improved robustness and scalability:
- Disco Distributed Filesystem:
- Improved blob placement policy.
- Atomic set updates (update=1).
- Delayed commits (delayed=1), which gives a major performance boost without sacrificing data consistency.
- Garbage collection is now scheme-agnostic (#189).
- Major DiscoDB enhancements:
- Values are now compressed without sacrificing performance.
- Constructor accepts unsorted key-value pairs.
- Option (unique_items=True) to remove duplicates from inputs automatically.
- unique_values() iterator.
Alternative signature for reduce: Reduce can now yield key-value pairs (or return an iterator) instead of calling out.add() (see disco.func.reduce2()).
Enhanced Java support added as a Git submodule under contrib/java-ext (Thanks to Ryan Maus).
Disk space monitoring for DDFS added to the Web UI.
Lots of enhancements to disco command line.
New setting DISCO_SORT_BUFFER_SIZE to control memory usage of the external sort (see disco.settings).
disco.func.gzip_reader() for reading gzipped inputs.
Easier single-node installation with default localhost configuration.
Deprecated¶
Important! The default reader function, disco.func.map_line_reader(), will be deprecated. The new default is to iterate over the object returned by map_reader. In practice, the default map_reader will still return an object that iterates over lines. However, it will not strip newline characters from the end of lines as the old disco.func.map_line_reader() does.
Make sure that your jobs that rely on the default map_reader will handle newline characters correctly. You can do this easily by calling string.strip() for each line.
Backwards incompatible changes¶
- Installation script for Amazon EC2 removed (aws/setup-instances.py) and documentation updated accordingly (see How do I use Disco on Amazon EC2?). Disco still works in Amazon EC2 and other similar environments flawlessly but a more modern mechanism for easy deployments is needed.
Bugfixes¶
- Critical bug fixes to fix partition file handling and save=True behavior under temporary node failures (see a separate note above).
- Delayed commits in DDFS fix OOB slowness (#155)
- Fix unicode handling (#185, #190)
- In-memory sort disabled as it doesn’t work well compressed inputs (#145)
- Fixed/improved replica handling (#170, #178, #176)
- Three bugfixes in DiscoDB querying and iterators (#181)
- Don’t rate limit internal messages, to prevent bursts of messages crashing the job (#169)
- Random bytes in a message should not make json encoding fail (#161)
- disco.core.Disco.wait() should not throw an exception if master doesn’t respond immediately (#183)
- Connections should not fail immediately if creating a connection fails (#179)
- Fixed an upload issue in comm_pycurl.py (#156)
- Disable HTTP keep-alive on master.
- Sort failing is not a fatal error.
- Partitioned only-reduce did not check the number of input partitions correctly.
- DISCO_PROXY did not work correctly if disco was run with a non-standard port.
- node_mon didn’t handle all messages from nodes correctly, which lead its message queue to grow, leading to spurious Node unavailable messages.
- Fix mouse-over for showing active cores in the status page.
Disco 0.3 (May 26th 2010)¶
New features¶
- Disco Distributed Filesystem - distributed and replicated data storage for Disco.
- Discodex - distributed indices for efficient querying of data.
- DiscoDB - lightning fast and scalable mapping data structure.
- New internal data format, supporting compression and pickling of Python objects by default.
- Clarified the partitioning logic in Disco, see Data Flow in MapReduce Disco Jobs.
- Integrated web server (Mochiweb) replaces Lighttpd, making installation easier and allows more fine-grained data flow control.
- Chunked data transfer and improved handling of network congestion.
- Support for partial job functions (Thanks to Jarno Seppänen)
- Unified interface for readers and input streams, writers deprecated. See disco.core.Disco.new_job().
- New save=True parameter for disco.core.Disco.new_job() which persists job results in DDFS.
- New garbage collector deletes job data DISCO_GC_AFTER seconds after the job has finished (see disco.settings). Defaults to 100 years. Use save=True, if you want to keep the results permanently.
- Support for Out-of-band (OOB) results implemented using DDFS.
- disco-worker checks that there is enough disk space before it starts up.
- discocli - Command line interface for Disco
- ddfscli - Command line interface for DDFS
- Improved load balancing in scheduler.
- Integrated Disco proxy based on Lighttpd.
- Debian packaging: disco-master and disco-node do not conflict anymore, making it possible to run Disco locally from Debian packages.
Deprecated¶
- These features will be removed in the coming releases:
- object_reader and object_writer - Disco supports now pickling by default.
- map_writer and reduce_writer (use output streams instead).
- nr_reduces (use partitions)
- fun_map and input_files (use map and input)
Backwards incompatible changes¶
- Experimental support for GlusterFS removed
- homedisco removed - use a local Disco instead
- Deprecated chunked parameter removed from disco.core.Disco.new_job().
- If you have been using a custom output stream with the default writer, you need to specify the writer now explictly, or upgrade your output stream to support the .out(k, v)` method which replaces writers in 0.3.
Bugfixes¶
- Jobs should disappear from list immediately after deleted (bug #43)
- Running jobs with empty input gives “Jobs status dead” (bug #92)
- Full disk may crash a job in _safe_fileop() (bug #120)
- Eventmonitor shows each job multiple times when tracking multiple jobs (bug #94)
- Change eventmonitor default output handle to sys.stderr (bug #83)
- Tell user what the spawn command was if the task fails right away (bug #113)
- Normalize pathnames on PYTHONPATH (bug #134)
- Timeouts were handled incorrectly in wait() (bug #96)
- Cast unicode urls to strings in comm_curl (bug #52)
- External sort handles objects in values correctly. Thanks to Tomaž Šolc for the patch!
- Scheduler didn’t handle node changes correctly - this solves the hanging jobs issue
- Several bug fixes in comm_*.py
- Duplicate nodes on the node config table crashed master
- Handle timeout correctly in fair_scheduler_job (if system is under heavy load)
Disco 0.2.4 (February 8th 2010)¶
New features¶
- New fair job scheduler which replaces the old FIFO queue. The scheduler is inspired by Hadoop’s Fair Scheduler. Running multiple jobs in parallel is now supported properly.
- Scheduler option to control data locality and resource usage. See disco.core.Disco.new_job().
- Support for custom input and output streams in tasks: See map_input_stream, map_output_stream, reduce_input_stream and reduce_output_stream in disco.core.Disco.new_job().
- disco.core.Disco.blacklist() and disco.core.Disco.whitelist().
- New test framework based on Python’s unittest module.
- Improved exception handling.
- Improved IO performance thanks to larger IO buffers.
- Lots of internal changes.
Bugfixes¶
- Set LC_ALL=C for disco worker to ensure that external sort produces consistent results (bug #36, 7635c9a)
- Apply rate limit to all messages on stdout / stderr. (bug #21, db76c80)
- Fixed flock error handing for OS X (b06757e4)
- Documentation fixes (bug #34, #42 9cd9b6f1)
Disco 0.2.3 (September 9th 2009)¶
New features¶
- The disco.settings control script makes setting up and running Disco much easier than before.
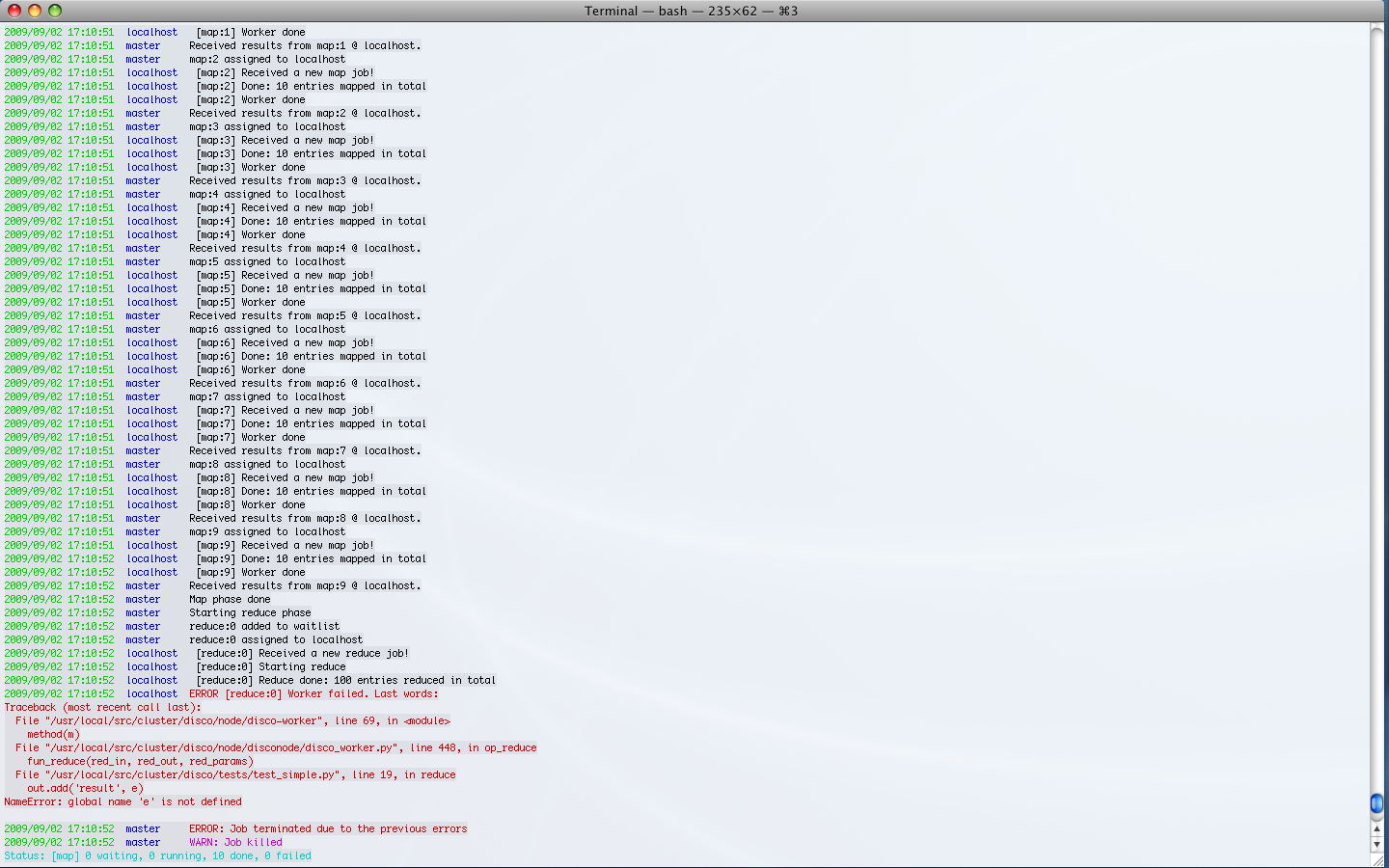
- Console output of job events (screenshot). You can now follow progress of a job on the console instead of the web UI by setting DISCO_EVENTS=1. See disco.core.Disco.events() and disco.core.Disco.wait().
- Automatic inference and distribution of dependent modules. See disco.modutil.
- required_files parameter added to disco.core.Disco.new_job().
- Combining the previous two features, a new easier way to use external C libraries is provided, see disco.worker.classic.external - Classic Disco External Interface.
- Support for Python 2.6 and 2.7.
- Easier installation of a simple single-server cluster. Just run disco master start on the disco directory. The DISCO_MASTER_PORT setting is deprecated.
- Improved support for OS X. The DISCO_SLAVE_OS setting is deprecated.
- Debian packages upgraded to use Erlang 13B.
- Several improvements related to fault-tolerance of the system
- Serialize job parameters using more efficient and compact binary format.
- Improved support for GlusterFS (2.0.6 and newer).
- Support for the pre-0.1 disco module, disco.job call etc., removed.
{kind=link}
Bugfixes¶
- critical External sort didn’t work correctly with non-numeric keys (5ef88ad4)
- External sort didn’t handle newlines correctly (61d6a597f)
- Regression fixed in disco.core.Disco.jobspec(); the function works now again (e5c20bbfec4)
- Filter fixed on the web UI (bug #4, e9c265b)
- Tracebacks are now shown correctly on the web UI (bug #3, ea26802ce)
- Fixed negative number of maps on the web UI (bug #28, 5b23327 and 3e079b7)
- The comm_curl module might return an insufficient number of bytes (761c28c4a)
- Temporary node failure (noconnection) shouldn’t be a fatal error (bug #22, ad95935)
- nr_maps and nr_reduces limits were off by one (873d90a7)
- Fixed a Javascript bug on the config table (11bb933)
- Timeouts in starting a new worker shouldn’t be fatal (f8dfcb94)
- The connection pool in comm_httplib didn’t work correctly (bug #30, 5c9d7a88e9)
- Added timeouts to comm_curl to fix occasional issues with the connection getting stuck (2f79c698)
- All IOErrors and CommExceptions are now non-fatal (f1d4a127c)
Disco 0.2.2 (July 26th 2009)¶
New features¶
- Experimental support for POSIX-compatible distributed filesystems, in particular GlusterFS. Two modes are available: Disco can read input data from a distributed filesystem while preserving data locality (aka inputfs). Disco can also use a DFS for internal communication, replacing the need for node-specific web servers (aka resultfs).
Bugfixes¶
- DISCO_PROXY handles now out-of-band results correctly (commit b1c0f9911)
- make-lighttpd-proxyconf.py now ignores commented out lines in /etc/hosts (bug #14, commit a1a93045d)
- Fixed missing PID file in the disco-master script. The /etc/init.d/disco-master script in Debian packages now works correctly (commit 223c2eb01)
- Fixed a regression in Makefile. Config files were not copied to /etc/disco (bug #13, commit c058e5d6)
- Increased server.max-write-idle setting in Lighttpd config. This prevents the http connection from disconnecting with long running, cpu-intensive reduce tasks (bug #12, commit 956617b0)
Disco 0.2.1 (May 26th 2009)¶
New features¶
- Support for redundant inputs: You can now specify many redundant addresses for an input file. Scheduler chooses the address which points at the node with the lowest load. If the address fails, other addresses are tried one by one until the task succeeds. See inputs in disco.core.Disco.new_job() for more information.
- Task profiling: See How do I profile programs in Disco?
- Implemented an efficient way to poll for results of many concurrent jobs. See disco.core.Disco.results().
- Support for the Curl HTTP client library added. Curl is used by default if the pycurl module is available.
- Improved storing of intermediate results: Results are now spread to a directory hierarchy based on the md5 checkum of the job name.
Bugfixes¶
- Check for ionice before using it. (commit dacbbbf785)
- required_modules didn’t handle submodules (PIL.Image etc.) correctly (commit a5b9fcd970)
- Missing file balls.png added. (bug #7, commit d5617a788)
- Missing and crashed nodes don’t cause the job to fail (bug #2, commit 6a5e7f754b)
- Default value for nr_reduces now never exceeds 100 (bug #9, commit 5b9e6924)
- Fixed homedisco regression in 0.2. (bugs #5, #10, commit caf78f77356)
Disco 0.2 (April 7th 2009)¶
New features¶
- Out-of-band results: A mechanism to produce auxiliary results in map/reduce tasks.
- Map writers, reduce readers and writers (see disco.core.Disco.new_job()): Support for custom result formats and internal protocols.
- Support for arbitrary output types.
- Custom task initialization functions: See map_init and reduce_init in disco.core.Disco.new_job().
- Jobs without inputs i.e. generator maps: See the raw:// protocol in disco.core.Disco.new_job().
- Reduces without maps for efficient join and merge operations: See Do I always have to provide a function for map and reduce?.
Bugfixes¶
(NB: bug IDs in 0.2 refer to the old bug tracking system)
- chunked = false mode produced incorrect input files for the reduce phase (commit db718eb6)
- Shell enabled for the disco master process (bug #7, commit 7944e4c8)
- Added warning about unknown parameters in new_job() (bug #8, commit db707e7d)
- Fix for sending invalid configuration data (bug #1, commit bea70dd4)
- Fixed missing msg, err and data_err functions (commit e99a406d)